Python
Python
python 实际上并不简单,只不过生态比较好。暴论:python 有多难用
我被 python 坑了太多次,甚至做了个 python-quiz讲述我的经历。
学习
python 入门非常快,简单看点 w3school 即可。进阶可以看一点 码农高天 的视频,虽然有一点炒作,但是不可否认他确实很强(为数不多的华人 python core dev)。
最后,不管学习什么语言都必须要做大量的项目。我也做了不少,例如 bpm 和 init-script。还有更多其他小项目,都是 AI 时代前潜心研究的。
安装
python 本身的安装应该不用我多说,windows scoop / archlinux pacman 一行结束。不过注意,没有启用虚拟环境时,电脑中最好只有一个 python。
开发环境
查看 external 8. 以进行参考。
vscode
关于开发,我直接无脑 all in vscode。
开发 python 前,强烈建议安装以下扩展:
- Python - Microsoft
- Ruff - Charlie Marsh:linter + formatter + highlighter
- 配置技巧
- ruff 的 formatter 几乎与 black 兼容,因此可以放心用。
- python 的代码风格非常统一,是一件好事。(反观隔壁
.clang-format行数)
- python 的代码风格非常统一,是一件好事。(反观隔壁
- Pyrefly - meta,python linter,平替 Pylance 而且还快。
Pylance - Microsoft,主要用于提供 inlay hints 和 type checker。inlay hints 比较重要,可以提早发现问题。之前被坑过。inlay hints 默认关闭,需要手动开启。在设置里搜inlay hints,把 Pylance 提供的四个都开起来。
- 其他扩展可选:
(optional) isort - Microsoft:提供 import 排序,formatter。如果用 ruff 就不需要这个了(optional) Black Formatter - Microsoft:formatter如果用 ruff 就不需要这个了
我的配置
"[python]": {
"editor.defaultFormatter": "ms-python.black-formatter",
"editor.formatOnType": true,
"editor.formatOnSave": true,
"editor.codeActionsOnSave": {
"source.fixAll": true,
"source.organizeImports": true
}
},
"python.analysis.inlayHints.pytestParameters": true,
"python.analysis.inlayHints.variableTypes": true,
"python.analysis.inlayHints.functionReturnTypes": true,
"python.analysis.inlayHints.callArgumentNames": "all",
"python.analysis.typeCheckingMode": "standard",该配置在保存时自动格式化,并开启一些有用的提示。
启用虚拟环境
创建虚拟环境并引入依赖后,代码仍会收到 vscode 的报错:

解决方法:
Ctrl + Shift + P打开命令面板,搜索Python: Select Interpreter- 选中你的虚拟环境。如果没有自动检测到,就手动打开路径,选择
.venv/Scripts/python或.venv/bin/python。
包管理器
python 的包管理器可以说是百花齐放。
对于 python 包管理器,我的基本需求是:1. 帮我打包 + 上传 2. 支持 PEP 621。
uv
新的,用 rust 写的包管理器。现在也就出了没两年,赶上了 RIIR 的热潮,引起了很多话题。
2024.09 uv 在 v0.4.5 添加了 build 功能,于是我转向 uv。当然现在 uv 还存在一些问题,但是还是比 poetry 好用的。最大的优点就是快,并行下载安装实在是好用。
使用
uv 的使用与其他包管理器类似,也非常简单。
uv init # 新建项目
uv add <packages> # 添加包
uv remove <packages> # 移除包
uv sync # 更新 .venv,相当于 npm install
uv run python xxx.py # 使用该环境运行某个 py 文件
uv python pin 3.12 # 对当前项目使用某个 python 版本,如果没下载会自动下载
uv lock --upgrade && uv sync # 更新所有依赖- 不能在中文目录下
uv init,但是可以uv init --name xxx绕过。- 不能用中文做 package name 是 PEP 621 的要求。对于拿包管理器但是不用来写一个 python package 的人来说不太友好。
- 添加镜像:查看 issues#6925,Configuration files
- 不要同时使用
uv pip install和uv add,pip 安装的不会写入 toml,在uv run时会自动 sync 导致 pip 安装的包丢失。 - uv 官方其实有安装 pytorch 的教程。
- build 时默认会把目录下所有文件都放进来。如果需要选择性放入文件,可以用
[tool.hatch.build] include = ["*.py"] - 永远不要在 CI 或其他地方使用
--locked。(src)
使用 uv-migrator 可以将其他大部分包管理器的配置无缝迁移到 uv。
我的配置
~/uv.toml:
index-url = "https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple" # 全局换源
prerelease = "allow" # 不再禁止 prerelease 包pdm
国人开发,据说很好用,除了性能以外没有其他问题。
主要开发者是 frostming,非常活跃并积极解决问题。
之前 pdm 不允许在中文目录下 init,并且没有类似 uv 的 --name 方法绕过。我在论坛上提了一嘴,然后被看到了,就修了。
poetry
广泛使用的老牌 python 包管理器,指令抄的 npm。略胜 miniconda。
poetry 可以说是我用的最久的 python 包管理器了。弃坑原因主要是因为:
- 其不兼容 PEP 621,因为 poetry 出道的时候 PEP 621 还没有出现呢。
- dep resolve 太慢了。
- 有更多更好的新兴包管理器。
安装
这里是官方教程。poetry 在 windows 上的 install script 可谓傻逼[1],开代理不能装,关代理不能装,scoop 用的也是官方 install script。只好使用 pip。
pip install poetry -i https://pypi.tuna.tsinghua.edu.cn/simple配置
- poetry 默认在某个集中的位置(Windows:
C:,Linux:~/.cache/...)创建虚拟环境。这不利于使用,特别是当在 vscode 中选择 python 解释器时。明明抄的 npm,为什么不像 npm 那样把依赖都放在项目下呢? - poetry windows 默认在 C 盘缓存。空间吃紧的话可以把缓存转到其他盘。
poetry config virtualenvs.in-project true
poetry config cache-dir Z:\换源
身在中国,换源是很重要的(python 不走代理[1:1])。最好每次创建项目都换源,这样一起协作的其他人都无需手动换源。参考文档。
- 命令行换源
poetry source add tsinghua-pypi https://pypi.tuna.tsinghua.edu.cn/simple - 手动换源:编辑
pyproject.toml[[tool.poetry.source]] name = "tsinghua-pypi" url = "https://pypi.tuna.tsinghua.edu.cn/simple" priority = "default"
基本命令
- 新建项目:
poetry new <package name>- 创建 .toml 文件:
poetry init,然后跟着提示填入信息
- 创建 .toml 文件:
- 包管理
- 添加包:
poetry add <package name> - 移除包:
poetry remove <package name> - 列出可用包:
poetry show
- 添加包:
- 安装依赖
- 从现有
pyproject.toml安装:poetry install,会自动新建虚拟环境 - 从
requirements.txt安装(不够完善):cat requirements.txt | xargs -I % sh -c 'poetry add "%"'(ref)
- 从现有
- 虚拟环境
- 激活:
poetry shell(或在虚拟环境目录执行call activate.bat) - 删除:
poetry env remove --all
- 激活:
- 运行:
poetry run python <filename>.py
miniconda
提供 python 包管理与虚拟环境。我已弃用 miniconda。
Anaconda 体积过于庞大(6G+),强烈建议安装 miniconda。Anaconda 捆绑祸害了多少编程新人!(包括我) windows 可以使用 scoop 一行搞定。
基本命令
conda create -n <name> python=<version> # 创建环境
conda create -n <name> --clone <FromEnv<name>> # 迁移环境
conda info -e # 查看环境
conda activate <name> # 唤醒环境
conda deactivate # 关闭环境
conda remove -n <name> --all # 删除环境,也可进入 conda 安装目录下的 /envs/ 删除文件夹
conda list # 查看环境内工具包高级技巧
- bat 文件中调用 conda 指令:调用前加入
call activate.bat指令 - 创建纯净环境:我们使用上述指令创建环境后,可以看到,conda 帮我们预装了很多实际上没什么用的包,这无疑会让打包出的程序增加不必要的体积。
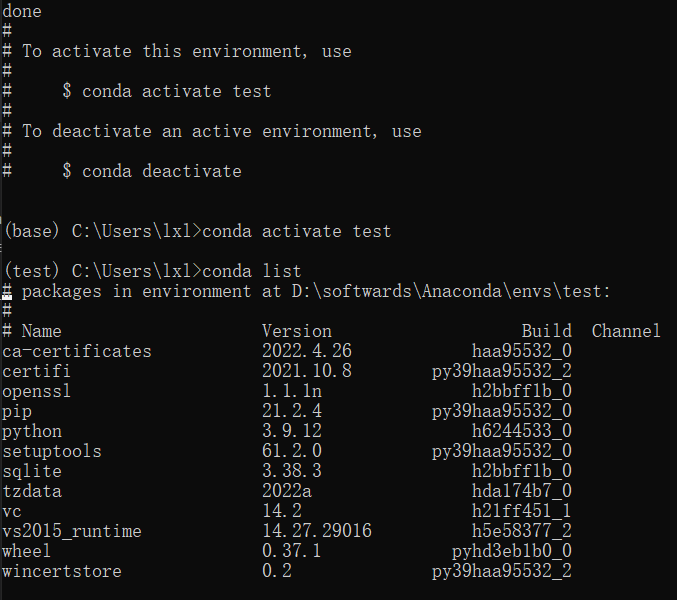
预装了很多实际上没什么用的包 - 在任意目录下新建文件,输入以下内容并保存为
env.txt(名字不重要)。
@EXPLICIT https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/win-64/python-3.9.7-h6244533_1.tar.bz2 https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/win-64/pip-21.2.4-py39haa95532_0.tar.bz2 https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/win-64/setuptools-58.0.4-py39haa95532_0.tar.bz2- 该目录下执行
conda create --name <name> --file env.txt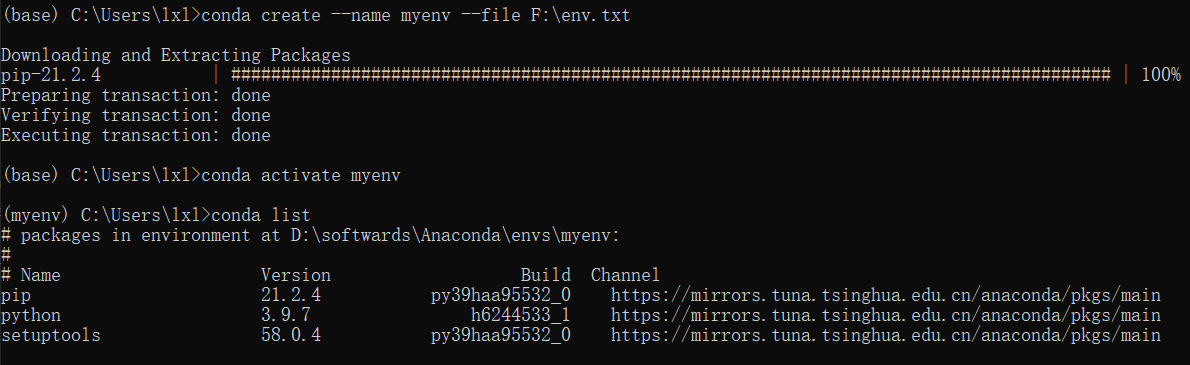 这样,一个纯净环境就创建好了,你可以安装 Pyinstaller进行打包前的准备。
这样,一个纯净环境就创建好了,你可以安装 Pyinstaller进行打包前的准备。
- 在任意目录下新建文件,输入以下内容并保存为
pip
python(windows 下)自带的包管理器。其使用一个全局环境,如果需要局部环境,需要与 venv 结合。
pip 使用 requirements.txt 用于声明项目依赖,使用时只需 pip install -r requirements.txt 即可。该文件可以用 pip 导出,也可以自己写模块。可以不写版本,只写每行一个模块名。
还有一些 rewrite to rust 的包管理器,例如 rye, pixi,底层调用的都是 uv。它们也没有更多吸引我的 feature,因此只需要用 uv 就行了。
语言相关
基本概念
- python 函数传参跟其他语言很像,基本类型是值传递,object, list, dict 是引用传递。
- 不想传引用就有深拷贝和浅拷贝,这个应该是编程基本概念而不是语言基本概念。
- python 的类型标注只会报警告,运行时不检查。
- python 不支持重载。
- python 的 OOP 是残缺的,即使可以靠一些装饰器逼近。
- 比较偏门的是,
else可以与try-catch或 循环 一起使用。
作用域
每个函数自身是一个作用域。python 在作用域内部可以直接读取外部作用域变量,但是无法修改。想要修改外部作用域变量,需要进行“捕获”(非专业用词),使用 global xxx 捕获全局变量,使用 nonlocal xxx 捕获上一级变量。在捕获变量后就可以修改了:xxx = 1,并且可以在其他作用域看到这一次修改。
函数
- python 函数参数里,位于
/前面的参数都必须使用不带等号的形式,*后面的参数都必须使用 k=v 形式。
错误处理
- py 错误处理偏向传统的异常处理。主要关键字是
try,except,else,finally。 finally能在return和exit时执行,但不能在 SYSTERM,os._exit()时执行。src
module
每个目录 / .py 文件都被视作一个模块。目录模块要添加内容,要写在目录下的 __init__.py。
import xxx 在顶层找模块,import .xxx 是在当前目录找模块,..xxx 是在上一层找,...xxx 以此类推。以 import . 开头的模块引用都是相对引用。使用相对引用时,不能直接 python xxx.py 执行代码,需要 python -m <root_module>.<submodule> 当成模块执行。否则报 ImportError: attempted relative import with no known parent package。
import 和 from import 都会导入整个模块,即使只用 from import 导入了一个函数。模块不能循环导入(不能在 A 中 import B,在 B 中 import A),即模块引用结构需要是 DAG。
import .xxx.yyy 不会引用到 xxx。
打印错误信息的时候记得加 file=sys.stderr,打到 stderr。很容易忘。
assert
都写 py 了,性能已经不敏感了,不如多做点防御性编程。
assert need_be_true(), "error message"assert 的 error message 不是 & 不能改红色,还会打堆栈,让我很不爽。
实际上在使用测试时基本上用的都是测试框架自己的 assert,优势是可以打印值。用系统 assert 一般只是拿来防御性编程。
我写过一个 pretty-assert,可以打出 assert diff,不过貌似有点小问题,不建议在生产环境使用。
传参
- 解耦:
*是解 list,**是解 dict。但是要注意,使用条件很严格,参数不能多也不能少。我没有找到一个比较好的设置 default 的方法。def fun(a, b): print(a, b) l = { "a": 1, "b": 2, } fun(**l) - 多参:类似的。这个倒是能较为简单地 set default。
def fun(*args, **kwargs): kwargs.setdefault("c", 3) pass fun(1, 2, a=1, b=2) # args: [1, 2] kwargs: {"a": 1, "b": 2, "c": 3}
Generator
Generator 其实是一个跨语言的概念,函数在执行到一半时可以先中断,将值传回,函数本身暂停;等到下次调用时再从中断处继续运行。
在函数里使用 yield 中断并返回值,函数本身就变成了 Generator,可以通过 next(gen) 推动 generator 执行一次。
def a():
for i in range(1,5):
yield i
b = a()
print(next(b))python 的 Generator 还可以传入值。这个用的少,第一次见到也不容易读懂用法。
def test():
while True:
x = yield 2
print(x)
c = test()
print(next(c))
print(c.send(1))
# 输出:2 1 2首先 Generator 执行到 yield 2,返回 2;接着向其 send 一个 1,Generator 将 (yield 2) 本身作为 1,继续执行,打印出 1,并在下一次 yield 2 返回。相当于一个传值 + next。
并发
多线程(threading)和多进程(multiprocessing)属于比较重的并发,用于计算密集型,不适用于网络 & IO。一般网络等使用 asyncio 进行协程并发。
下面是一个用协程的例子。
import asyncio
async def xxx(i):
return i
async def main():
a = []
for i in range(10):
a.append(xxx(i))
x = await asyncio.gather(*a)
print(x)
asyncio.run(main())
# 打印 1-10,表明 gather 的结果是有序的。python 的 async/await 也具有染色性质,导致很多地方同一个代码要写 async 和非 async 两个版本,这是当前版本的一个痛点,还没有优雅的解决方法。
也有一些第三方库,例如 anyio 和 trio,可以用于并发,但是我觉得那些 API 的设计都不算太好,asyncio 就够用了。
语法糖
format string
只要不是对向前兼容性要求非常高的程序,一般都使用 f-string (>=python 3.6),而不是 % 这种老方法了。你喜欢 cout 还是 printf?
不讲太多格式化,讲一个:
a = 1
print(f"{a = }")
# a = 1打日志挺方便的。
map & filter
a = [1, 2, 3]
b = [i**2 for i in a if i <= 2]
# b = [1, 4]当然也有正经的 map() & filter(),不过还要转回 list,还要嵌套一堆括号,看着确实丑。
supress
“抑制”
from contextlib import suppress
with suppress(Exception):
something_could_go_wrong()
# 能少写两行。等价于
# try:
# something_could_go_wrong()
# except Exception:
# passwalrus operator
if 和 while 里创建临时变量用的。简单清晰,容易控制生命周期。可惜局限性还是挺大的。
Decorator
装饰器本质上是回调的语法糖。external 3. 是一篇讲的很好的装饰器文章。external 9. 介绍了装饰器与 class 混杂使用的技巧。
builtin decorators
这篇文章讲了一些常用的自带装饰器,主要是重载,OOP。
functools.lru_cache:当函数入参相同时,重复利用缓存。- 也有一个
functools.cache,==lru_cache(maxsize=None)(ref)
- 也有一个
dataclasses.dataclass:自动生成函数,简化开发。
match
python 在 3.10 引入了 match 语法,并且可以在 case 中接 if。但是 match 有两个缺点:
- 3.10 对保守派是很高的要求。对于一些老库来说,为了兼容性考虑,它们往往不会选择
match。 - match 和 case 需要两个缩进,而
if-elif链只需要一个缩进。
自带模块
这里的模块都不需要额外安装。python 自带。
pprint
pretty-print,打印嵌套数据结构比较好看。pprint 不能打印 object 信息。
from pprint import pprint
pprint({"a": 1, "b": 2}) # {'a': 1, 'b': 2}
pprint(an_obj) # <__main__.o object at 0x00000234DC0FAF60>configparser
configparser 做 config 对客户而言比较新手友好,至少不会像 json 那样多加或少加尾随逗号 ,。
当然现在用自定义 ini 已经 out 了,否则兼容性非常差。尽可能使用 toml/json/yaml 等通用格式才是正道。特别是 toml 和大部分 ini 长得都挺像的,迁移也方便。
from configparser import ConfigParser
config = ConfigParser()
config.read("config.ini") # 读
config.get(section, option, fallback="") # 获取(带默认值)
config[section][option] = value # 新增 / 修改
with open("config.ini", "w") as configfile:
config.write(configfile) # 写configparser 被设计成尽可能兼容所有 config,因此可以自定义分隔符,注释符等。
subprocess
写脚本必不可少的东西,可以向终端发出信息。代替 os.system()。
from subprocess import run # 官方建议使用 run 代替所有其他低阶函数
run("ls", "-al", check=True) # check=True 表示遇到错误则发出异常,= run(..).check_returncode()
run("ls | grep py", shell=True) # shell=True 无需拆分命令,如果碰到管道或复杂指令还是不要难为自己
run("ls", "-al", capture_output=True, text=True).stdout # 以字符串获取输出pathlib
操作文件的高阶抽象。用过 pathlib 以后就再也回不去 os 了()
from pathlib import Path
Path(Path("123")) # 碰到不清楚是 str 还是 Path 的路径,可以无脑转为 Path
Path("xxx") / "asd" # 连接路径(理解为重载了 / 号)
str(Path("xxx").absolute()) # 返回绝对路径字符串
Path("a.py").read_text(encoding="utf-8") # 读取,write_text 是写入
Path("a.db").read_bytes() # 读取,write_bytes 是写入
Path("a.py").unlink() # 删除文件
Path("a.py").rmdir() # 删除文件夹
# 也可以做到创建(touch),改权限(chown),链接(hardlink_to)等等,边用边搜。timeit
benchmark.
from timeit import timeit
def a():
pass
print(timeit(a,number=10000))pickle
对象序列化极为简单无脑。弱类型语言的大优势。
import pickle
...
soup = BeautifulSoup(response.content, "html.parser")
with open("soup.test", "wb") as f:
pickle.dump(soup, f) # serialize
with open("soup.test", "rb") as f:
soup = pickle.load(f) # deserialize可以用 pickle 实现一个简单的 cache。
urllib
处理 url 请使用 urllib,否则怎么死的都不知道。
构造 url 可以用 posixpath.join() + urllib.parse.join() (ref)
tempfile
跨平台获取临时文件夹。用来测试文件操作比较好用。
from tempfile import TemporaryDirectory
with TemporaryDirectory() as tmp_dir:
tmp_dir = Path(tmp_dir) # tmp_dir 是 str
# 离开作用域自动销毁pytest 有内置 tmp_dir。
常用外部包
pandas
数据表处理库,一般用来处理 ms 那堆玩意。
import pandas as pd
file = pd.ExcelFile("a.xlsx")
for name in file.sheet_names:
sheet = pd.read_excel(file, sheet_name=name)
for _, row in sheet.iterrows():
print(row["姓名"])我个人是不喜欢用 pandas 的,因为它的语法过于晦涩诡异[2]。如果需要读取 csv/xlsx,可以查看 external 5. Fastest Way to Read Excel in Python 选择其他工具。
一行代码更换 pandas 后端,可以大幅提升读取速度。(src)
第三方包推荐
log
虽然 python 有自带的 logging,但是用得多了,每次写项目前起手一长串配置确实有点烦人。所以我现在用 loguru,直接 from loguru import logger 然后正常用就行,自带彩色输出,配置起来也简单。
logger.add(filepath)会 copy 一份输出 append 到文件。
网络
python 界最常用的网络库 requests 是不支持 async 的!然而网络不能没有 async,因此建议大家可以直接抛弃 request 换用其他的库,这样也符合解耦论。
一个选择是大声对标 requests 的 grequests,但是我看了一下 README 里的 API,内部 async 但是不在外部暴露,虽然 99% 的网络需求都能通过 batch process 解决,但是不暴露 async 还是不够解耦不够自由。
httpx 拥有更简洁的 API 和一个 cli 用于快速测试;虽然其默认是同步 API 但也支持异步,用 asyncio 或 trio 作为异步运行时。
aiohttp 是一个真正的 async 网络库,甚至同时支持 server/client mode。它暴露所有 async 接口,并且与 python 标准的 asyncio 配合,拥有较高的可扩展性,可以实现复杂需求。要我说缺点的话,那就是线程池 session 对用户不是无感知的,比全局 context poll 要差。
命令行参数
- python 自带了一个 argparse 模块用于命令行 parse。虽然由于有官方支持,这个包是命令行参数 parse 中最泛用的一个,但是用起来还是不够顺手,语法也比较丑。这里是一个例子(我写的 bin-package-manager 用的 argparse),足以看出其不直观之处。
- click 是一个专门用于命令行参数 parse 的库,它使用装饰器嵌套的方式实现简洁直观的语法。缺点是自由度不高,不适合太大的项目。
- 如果需要 short command 还需要引入 click-aliases。
- 此外还有 cappa 库使用 dataclass 进行命令行 parse,模仿的是 rust 的 clap derived。这个方式同样也非常直观,不过该库在 2025 年还处于开发早期阶段,暂时不建议使用。
- python-fire 是 Google 官方的命令行工具,它致力于“把任何函数或其他东西变成命令行工具”。但是我认为它的语义设计本来就有问题,主打简单的结果就是扩展性差,很多时候没法清晰地表达我的复杂诉求。
命令行交互
很多时候我们需要让用户在几个选项中选择一个。自己写 input 的话还需要处理许多边缘情况,不如直接用现成的库。为了用户方便,我们甚至可以使用 TUI 进行引导。我尝试了一些库,在这里做一个总结。
- questionary:完美匹配需求,建议直接用
- simple-term-menu:不支持 windows;返回值的 typing 爆炸
- console-menu:不支持 interactive,与需求不符
- PyConsoleMenu:打包炸了,没法安装;底层的 windows-curses 有 bug
- PyConsoleMenu2:我自己 fork 了一个,解决打包问题,但是 windows-curses bug 还没解决,就是使用中文做标题/选项时在 windows 上会有奇怪的缩进。
- pymenu:极简 + full typing,但是只有颜色区分,不支持 prefix arrow,不直观
TUI
- rich 一家独大。不过都用 python 了,为什么不直接上 GUI 呢?好用的 GUI 也很多。
GUI
一些 GUI 框架。(大部分都没用过)
- CustomTkinter
- PySimpleGUI:真的很简单 / 简陋,but it works
- nicegui:基于 web 的
- Tkinter-Designer
- Flet:跨平台 Flutter 应用
- BeeWare(toga):原生跨平台
CustomTkinter
用过,文档没搜索功能,该有回调的地方不给回调,关联变量只能 get 不能 set。。。
系统需要有 tkinter,例如 archlinux 需要安装 tk。
爬虫与自动化
我其实只会一点简单的爬虫。简单的就 request + fake-useragent + BeautifulSoup4 html 解析,复杂一点的话直接模拟浏览器。
模拟浏览器
之前用过 playright 做一些疫情时的健康打卡相关(学长的项目),感觉一般。
然后寻找其他框架,发现一个国人写的 DrissionPage,虽然比较青涩,但是做一些简单的自动化非常简单。顺带提了个微小改进使用体验的 pr。
DrissionPage 用的是自创的元素选择器,需要看文档。这里有一个速查。一些需要注意的点:
@class=后面必须接上所有 class 包括空格,否则无法匹配。@text()=可以匹配深层子元素的 text。
以下是一个样例:
from DrissionPage import Chromium, ChromiumOptions
options = (
ChromiumOptions()
.set_argument("--remote-debugging-port=8888")
.set_user_data_path(r"Z:/chrome_tmp_data")
.set_local_port(8888)
.headless(False)
.set_browser_path(r"C:\Users\lxl\scoop\apps\ungoogled-chromium\current\chrome.exe")
)
browser = Chromium(options)
tab = browser.latest_tab
tab.get("https://public.ecustpt.eu.org/mybonus.php")
button = tab.ele("tag:input")
button.click()- 使用一个固定端口进行控制,而不是自动端口,因为 sing-box 高位端口开得多,自动端口可能会撞。
- set_user_data_path 让你重复运行浏览器脚本时可以保留 cookie 等数据,不需要重新登录。
图表绘制
用得最多的肯定是 matplotlib,但是它是从 matlab 过来的,而 matlab 的 API 设计是真的捞,写起来难受。所以有一些新的库可以尝试:
图像相关
图像相关基本就是 PIL 和 opencv 的天下了。不过能用 PIL 的我都不会用 opencv,因为 opencv binding API 本来就抽象,typing 一坨大便,打包还麻烦。把 PIL 的 Image 当成是标准的图像对象是一个符合工程实践的操作。
import requests
from PIL import Image
from io import BytesIO
response = requests.get(src)
image = Image.open(BytesIO(response.content))
image.show()from PIL import ImageGrab
img = ImageGrab.grab(bbox=(0, 0, 1920, 1080)) # 注意改为你需要截屏的分辨率我现在使用 typst,这个代码还是作废吧。
import img2pdf
temp = [BytesIO(...), BytesIO(...)]
# temp 也可以是字符串数组,包含本地图片路径
with open('第二册答案.pdf', "wb") as f:
write_content = img2pdf.convert(temp)
f.write(write_content)有时候需要对图片对象转为字节码以在不同函数间流通。(不统一对象的坏处)
import io
def img2Byte(img:Image) -> bytes:
imgByte=io.BytesIO()
img.save(imgByte,format='JPEG')
byte_res=imgByte.getvalue()
return byte_resfrom PIL import Image,ImageFilter
img = img.filter(ImageFilter.GaussianBlur(radius=1.5))使用此内置函数进行高斯模糊将无法改变 sigma 的值。
ORM
ORM (Object-relational mapping),数据关系映射。此处特指 python 实现的数据库 ORM。
最出名的 python ORM 应该是 sqlalchemy 吧。但是其文档比较烂,我觉得其设计并不哲学。所以我个人不喜欢这个。
然后是 django 的基于 model 的内置 ORM,由于使用 django 的人较多,因此也比较有影响力。我在下面有提到这个。
读过 pony 的文档与 tutorial 后,我觉得这个设计不错。
后端框架
FastAPI
FastAPI 是 python 里非常常用的 RESTful API 框架。我在我的毕设里也选用了这个框架。
FastAPI 并不 fast,不要被名字骗了。主要还是因为 asyncio 比较慢吧,人家以快著称的框架例如 FastWSGI 已经抛弃 asyncio,转用 libuv 了。
django
django 的前后端是深度耦合的,前端大概只能使用传统三件套(但是据说可以用 GraphQL 做中间层与框架式前端进行交互,没试过),后端自然就是 python 了。前后端耦合的设计在之前还挺受欢迎的,因为建站快。但是在后 AI 时代这个优势已经被磨平了。
数据库
由于我平常接触的不是 django 开发而是运维,所以这里主要讲讲数据库内容。
django 做了自己的基于模型的 ORM。django 官方支持这些数据库。
首先进行数据库操作前需要选择 model(可以理解为选表)。具体看 models.py 的实现。
from Djangoxxx.models import <module_name>然后根据需求选出 object 或者 queryset.
qs = <module_name>.objects.all()
obj = <module_name>.objects.get(id='xxx')
qs = <module_name>.objects.filter(FinishTime__range=[datetime(2023, 1, 1, 00, 00),datetime(2023, 11, 5, 00, 00)]) # 区间筛选 datetime再进行进一步处理。
c = qs.values_list('price', flat=True) # 获取某一列(colume)
print(c[0]) # 然后类似 list 形式操作取值
obj = qs.get(id='xxx') # 可以从 queryset 中取 object
print(obj.id) # 然后从 object 中取值取了值就可以爱干啥干啥了。我不太习惯高层次的抽象,因此类似求和啥的虽然 django 也提供了 django.db.models.Sum,但有查文档的功夫早都写好了,还是自己做吧。
调试
python 自带一个 pdb 调试器,非常方便,功能也很强大。Python 3.11 - 3.13 里 pdb 有许多改进。
使用:在程序中插入一个 breakpoint() 即可进入 pdb。
常见 pdb 命令:
| 命令 | 作用 |
|---|---|
| c (continue) | 继续运行 |
| n (next) | 下一步(不进入函数) |
| s (step) | 下一步(进入函数) |
| l (list) | 打印当前程序代码 |
| p (print) | 打印 |
| pp (pprint) | 美观打印 |
| ! (!var=xxx) | 更改变量 |
测试
python 测试的最佳实践是将测试写在模块外的 tests/ 里,但我并不喜欢。
unittest
我比较习惯单元测试,即将 test 函数与本身的定义写在一个文件里。因此可以直接使用最简单的 test 形式:
if __name__ == "__main__":
def test_xxx():
pass
test_xxx()当然,最好用自带的 unittest 包装一下,可以获取测试时间等。unittest 基础使用非常简单,具体的可以看文档用例。
python -m unittest ./**/*.py # 测试当前文件夹下所有 unittest,类似 `pytest .`但是 unittest 有个致命缺陷就是它支持 async function,但是不支持异步执行。。我非常无语。
pytest
这是一个复杂的测试框架。显然其支持异步执行测试用例,还有其他方便的特性。
使用 pytest 一般需要将测试代码放在其他文件里而不是代码所在文件,因为其对于 test 的文件名与函数名有特殊要求:代码文件名与函数名都需要以 test_ 开头或以 _test 结尾才会被默认测试。
提示
Google 中文用户搜 pytest 出来的第一个文档是 learning pytest,但是请不要看这个。比如它关于上述的 函数名/文件名限制 说的就是错的。
- 测试某个函数:
pytest <relative_path>::<function_name> - 永远显示 stdout 输出(包括 pass 时):
-s
兼容性测试
有时候需要跨 python 版本进行测试,或者找到最小支持的 Python 版本(Minimal supported Python version)。
首先,最朴素的手动测试要求电脑上安装不同的 python 版本。很多包管理器都不负责管理 python 版本,但是有一些可以:
uv python pin 3.12poetry env use <binary>至于其他非 python 包管理器的工具也可以安装不同版本的 python。有一些是本机。
windows 的 scoop 里有不同版本的 python。(python35 - python312)
archlinux 官方仓库只有最新版 python,但是 archlinuxcn 里有更低的版本。(python37 - python39)
pyenv 是一个 python 版本管理工具。不算太好用,我不能一键切换,得去找它的安装位置的 python 可执行文件。不过至少能用。
其次,如果有足够的 testcase,也可以考虑使用 nox,这是一个测试框架,不过我还没试用过。
性能分析
viztracer 是国人(高天)开发的性能分析工具,类似火焰图,十分简单易用。
- 安装 viztracer 和 VizTracer VS Code 插件
- 右击代码文件,选择
Trace with VizTracer - 在当前文件夹根目录找到
result.json,右击选择Open in VizTracer
import pstats
import cProfile
cProfile.run("my_function()", "my_func_stats")
p = pstats.Stats("my_func_stats")
p.sort_stats("cumulative").print_stats()打包
实际上 python 写的东西就应该传源码。如果需要打包的话不妨考虑换个语言。
nuitka
这玩意文档只能说一般,甚至没有 --help 好用。
安装(poetry):
poetry add --group dev nuitka我使用的打包指令:
nuitka3 --run --follow-imports --prefer-source-code --clang --disable-console --noinclude-pytest-mode=nofollow --noinclude-setuptools-mode=nofollow --plugin-enable=upx main.py--clang是选择 C 编译器,不用 clang 的话就不指定。--disable-console,因为我打包的是 GUI 程序。--plugin-enable=upx使用 upx 插件能够压缩程序大小。需要已安装 upx。
其他命令:自行
nuitka3 --help查看
发布
把包发布到 pypi,就能被 pip install 了。
- 注册一个 pypi 账号。
- 需要 2FA,用 github 的肯定不陌生。
- 需要申请一个 API token:account 向下滑就有。
- 使用工具构建并发布。uv
用 uv 打包一般会推荐使用 hatching(uv 不自己处理打包,而是用第三方库提供的打包功能):
[build-system] build-backend = "hatchling.build" requires = ["hatchling"] [tool.hatch.build] include = ["myprojectsrc/**"] packages = ["myprojectsrc"]然后 uv build 就行了
poetry参考此文。
- 写
pyproject.toml。- poetry 能够自动推断需要打包的模块。如果
name与 module name 不同,需要packages=[{include="..."}]。 - 如果目标是一个 binary,需要添加入口点。
[tool.poetry.scripts] <bin name> = '<module>:<function>'
- poetry 能够自动推断需要打包的模块。如果
- build & upload
poetry config pypi-token.pypi <API token> poetry publish --build
setuptools- 写
setup.py。可以用 GPT 生成,也可以去抄几份。 - 在
$HOME/.pypirc下写入[pypi] username = __token__ password = <API token> - 打包上传,工具任选。
- twine:
pipx install twine python3 setup.py sdist bdist_wheel twine upload dist/* --verbose - setuptools
python3 setup.py sdist upload
- twine:
- 写
其他工具
一些问题
为什么不该使用 pipx
历史事件
在一次迁移 python 的过程后,我再次使用 pipx 及其安装的软件,报错 python not found(指向我原先的 python 位置)。
我纳闷了,我直接 python 能用,也把所有环境变量全改成了新 python 的位置,检查了好几次,为啥还是不能用?
然后重装 pipx:
pip install --upgrade --force-reinstall pipx -i https://pypi.tuna.tsinghua.edu.cn/simple仍然不行。后来在 ~/.local/pipx/shared/pyvenv.cfg 找到了没改过的 python 路径。
原来你 TM 重装是不动配置文件的啊,卸了卸了。
后话:
- 正常的包管理器,例如 pacman,卸载时会将配置存为
*.pacsave - 路径不用环境变量存,就已经够奇怪了,更别说还保留 python 的绝对路径。。明明 python 自己有环境变量。
- pipx 安装甚至没有进度条。虽然说责任在 setuptools。
- pipx 只会为当前用户安装,而不是全局。
- 实际上对于全局用 pip,虚拟环境开 poetry 的我来说,pipx 确实是一个没必要存在的东西
- 但是在 linux 上不允许全局使用 pip,除非
--break-system-packages。所以 pipx 还是有用武之地的。
- 但是在 linux 上不允许全局使用 pip,除非
找不到 pip
执行 python -m pip install --upgrade pip 后报错:
ERROR: Could not install packages due to an OSError: [WinError 5] 拒绝访问。: 'c:\python310\scripts\pip.exe'
之后再使用 pip 命令时,就会不断报错,找不到 pip。我觉得很怪。C:\Python310\Scripts 路径下也能找得到 pip.exe,环境变量也没改。我在当前路径下打开 cmd ,执行 pip,然而还是不能正常使用。 (忘了报什么错了) 鼓捣了一会儿,试图使用离线安装,提示找不到 wheel.exe.
最终解决方法:在此处下载 .tar.gz,解压后在目录下执行:
python setup.py build
python -m pip install --upgrade pip --userexternal
- The Right Way to Run Shell Commands From Python
- Python 小整数与大整数的处理机制以及整体解释与逐行解释的区别
- Python 修饰器的函数式编程
- Python Type Hints 简明教程(基于 Python 3.12)
- Fastest Way to Read Excel in Python
- What the f*ck Python! 🐍 一些有趣且鲜为人知的 Python 特性.
- Python Gotcha: strip, lstrip, rstrip can remove more than expected
- How I manage Python in 2024
- 如何在 class 内部定义一个装饰器?
- Dive-into-cpython
- 再也别问 Singleton 了好吗?
- 14 Advanced Python Features - Edward Li's Blog
- fstrings.wtf:python fstring quiz